To automate a key workflow—syncing our master branch configuration to our dev-* environments—I created a robust Google Cloud Build pipeline.
Running event-driven microservices on GKE using KEDA is fantastic for cost efficiency and scalability.
The goal was simple: for every open pull request, automatically rebase its feature branch onto `master` and force-push the result.
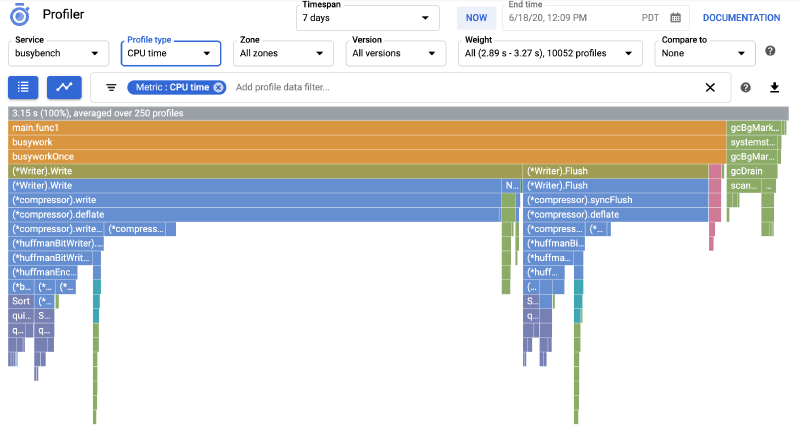
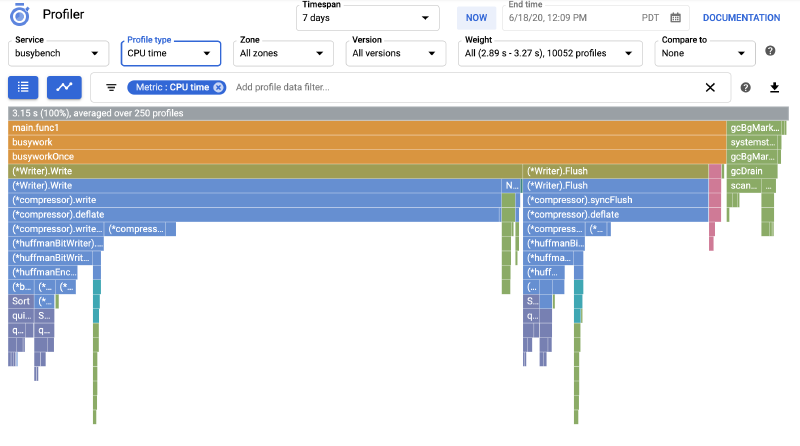
When you have K8s microservices, you want them to be fast, efficient, and cost-effective. But how do you know exactly where your code is spending its time or consuming resources? That's where a profiler comes in.
How I automated terraform-docs for our platform infrastructure repo using GCP Cloud Build and Docker
In this post, I’ll document how I approached organizing Terraform code for managing Auth0 tenants independently of the broader platform infrastructure.
Recently, I had to refactor our Terraform code and migrate the Terraform state file to a new GCP bucket. Fortunately, this was a straightforward migration, and I didn’t have to recreate any resources—just a quick state transfer was required. In this blog, I'll walk through the step-by-step process I followed to ensure a smooth and safe migration of our Terraform state.
Google Cloud Profiler is a continuous profiling tool that helps analyze CPU and memory usage in production environments with minimal overhead. It provides insights into performance bottlenecks, enabling teams to optimize their applications for efficiency and cost savings.
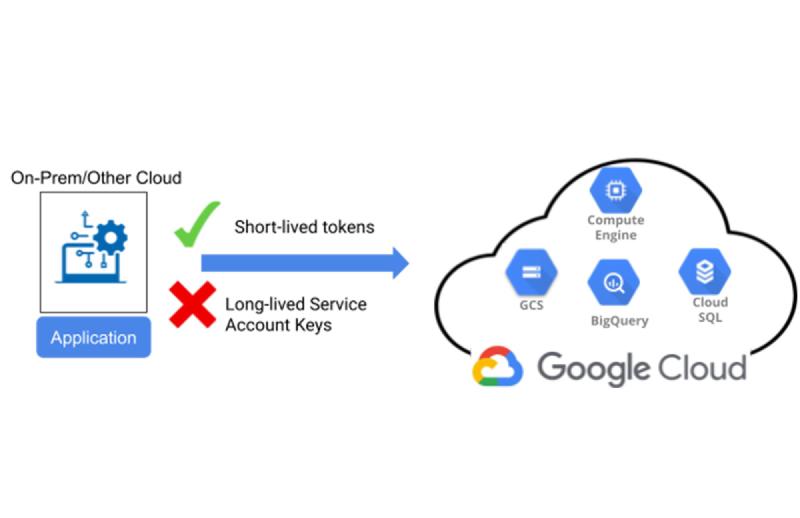
When running workloads in Kubernetes that need to access Google Cloud resources, a common approach has been to use a service account JSON key stored in a secret. However, this method has security vulnerabilities. Recently, I transitioned to using **Workload Identity Federation (WID)**, which eliminates the need for JSON keys while ensuring secure access. Here’s why WID is a game-changer and what I learned during this migration. 🚀
📌 This document outlines my experience implementing a Kubernetes microservice using KEDA (Kubernetes Event-Driven Autoscaling) to scale based on Pub/Sub messages. The focus is on how KEDA enables efficient scaling of workloads in response to event-driven triggers and the key lessons I learned along the way.